A Beginners Guide to Julia map(),mapreduce(), and Related Functions
The map family of functions, including map(), mapreduce(), mapfoldl(), and mapfoldr() have quickly become some of my favorite and most used functions in the Julia language. The funny part about them though is that it took me a long time before I started using them. There was something "foggy" about them in my mind. I knew roughly what they were meant to do, but until I started using them I didn't really "get it."
Do Syntax
The first problem I had with these functions is that they make heavy use of the do syntax from the language. This looks like:

This syntax is just a nicety for code readability. The two versions below are equivalent.
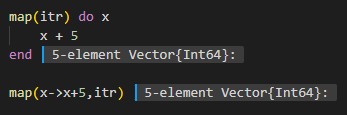
Here is what the Julia documentation says about the do keyword:
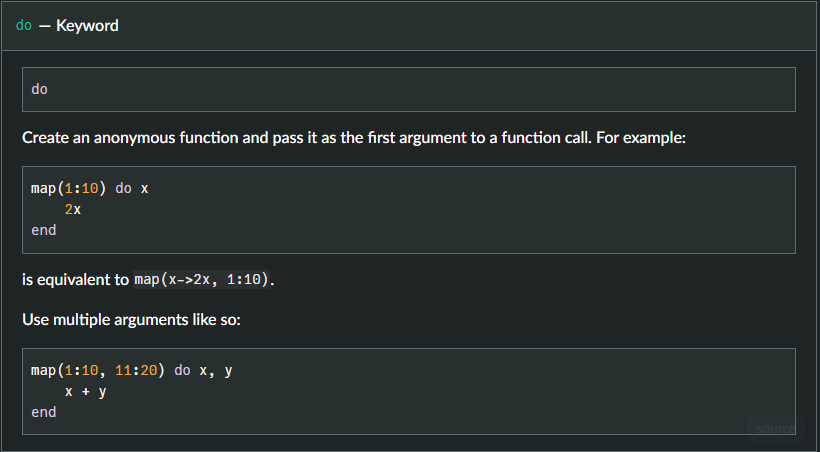
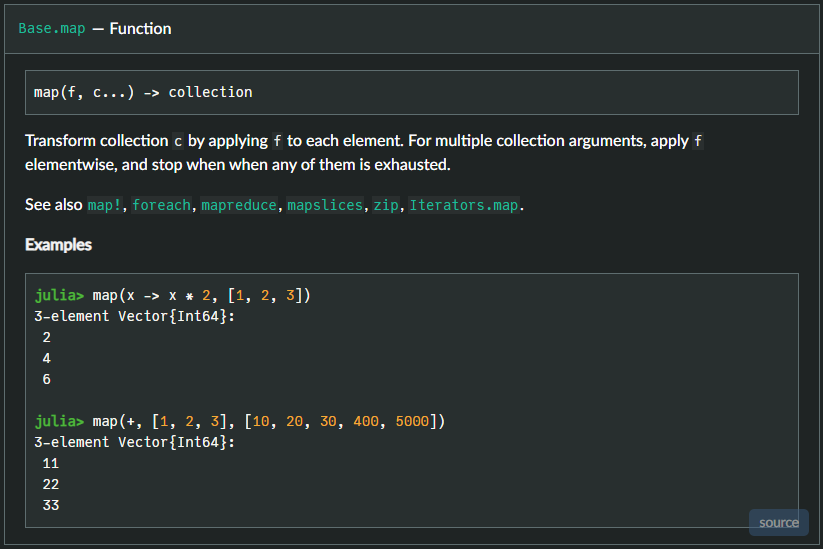
I don't know if I am dense or what, but that just didn't click with me. Especially when combined with the documentation for map():
I couldn't put together how we were getting from map to do. So here is how I had to translate this syntax into thinking.
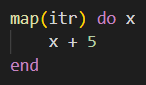
Translation: take each member of the iterable and call it x then perform all of the operations within the do block on that value of x, add the final value to a collection before repeating for each member. End by returning the collection.
Maybe I am dense, but this took a while to click. Do syntax is used anywhere a function signature looks like: funcName(function, iterable). If you function takes a function as the first argument it likely makes use of the do syntax by moving the function argument into the do block for readability.
Why Map?
Do syntax out of the way, I was still having a little trouble wrapping my mind around the map functions. Then one day it clicked, a map function is just a for loop with less writing. You just supply a function and an iterable and get back the result of running that function on every member of the iterable. Simple as that. But if I'm already comfortable with for loops, why use something else?
I'll put forth a few arguments for this. First, you can do more in less code. Consider that the following are functionally equivalent:
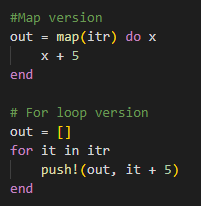
Mind you that here I have expanded map to its most verbose form and the for loop to its most concise. Map saves the need to create the container for the output or to push a value to that container. If we wanted to push this further you could use the parenthetical syntax and make the map call a very reasonable one liner.
Second, I think that map encourages thinking about things in a functional manner that builds in possibilities for free scalability and possibility of parallel computation. Map is based on the idea of a function in the sense from mathematics in that it maps a set of input values to a set of output values.
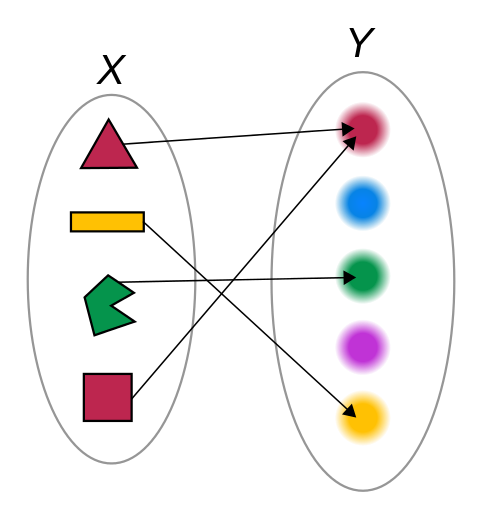
I really think this encourages you to back up a level and ask the question, "what is the generalized transformation I need to get my input to my output?" It moves you from thinking explicitly about each value as an individual process to thinking about the transformation in a generalized way. This thought pattern encourages baking in thinking about edge cases right from the get go. Additionally, all of the map functions are embarrassingly parallel since you are literally just applying the same function to each element. You could arbitrarily break up an iterable into x chunks, pass the function and chunks to different nodes or threads, run the transformation and concatenate the outputs and it just works.
Using the map() Family of Functions
The best recommendation I can give for newcomers is to think about a machine where you put one thing in and get one thing out. Now just hook up an iterable of a bunch of the in things and your map function will do the rest.
For example suppose we want to take everything in a list and square it. We would write:
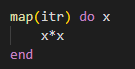
Notice the implicit return. You can also be explicit with the return, but the last answer returned is your implicit return. You can also do multi-step processes:
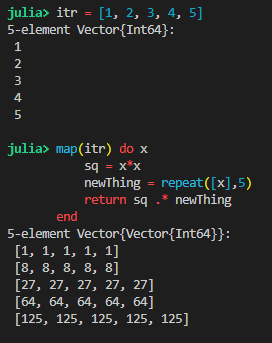
One of the features of map() that can make it a bit tricky to use at first is that the function returns a value for every iterable, so if there is nothing to return you will get a vector with values of nothing. For example:
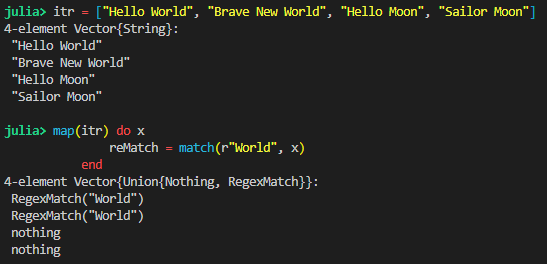
This behavior can be a little frustrating sometimes because you usually want the values, not the lack of values. The default behavior is to give you everything. No worries though a simple pipe to filter and you are back on your way.
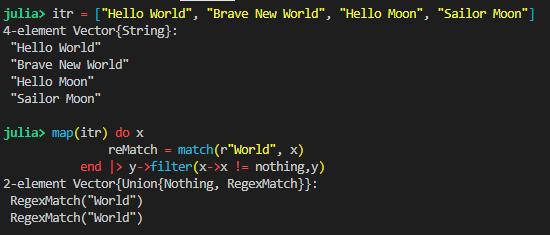
Just be careful that you know the size of your input and output are different.
mapreduce()
Mapreduce() adds a fun little feature in that it compresses your output to a single value by applying some reducing operator. Its signature is:

It basically does the same map function but then sequentially applies some reducing operator to combine the multiple answers into one value. A great example would be the sum of the squares of the first 5 numbers.
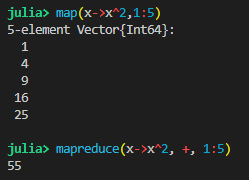
You can see that map reduce just takes the result of map and then applies the "+" operator sequentially 1+4+9+16+25. One thing to note is that addition is commutative, not all operations are. So there is the issue of order of operations. The official documentation says:
The associativity of the reduction is implementation-dependent. Additionally, some implementations may reuse the return value of f for elements that appear multiple times in itr. Use mapfoldl or mapfoldr instead for guaranteed left or right associativity and invocation of f for every value.
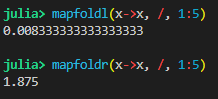
Basically that if the order in which you perform your reducing operator matters, then you need to be explicit on how you request the reduction:
Lately I have found this handy when looking at productivity data. I'll do something like load in a bunch of job completion data on a per person basis where each row essentially is a person and a work order and some data about completion of the work order. It will also include the shop as a designation. I found that a nice reusable pattern is to group the data by shop and then collect those individual groupings as dataframes. I then map the dataframes to complete whatever analysis I want and if I need to combine them I use map reduce. I use vcat() as the reduction operator to vertically concatenate (i.e. append each new df to the running dataframe). It ends up conceptually like this:
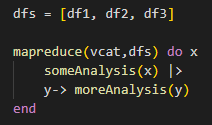
I like this approach because it lets me work with a subgrouping of the data for testing ( I generally start with a single item vector like test = [testDF]) and build out the map function until I'm getting the results I want. Then to scale up I just feed as many additional dataframes into the mapping function as needed. You may occasionally get some errors when one of your dataframes has an edge case that your test frame didn't. Generally I'm working with a normalized dataset so I have some data integrity assurances. Couple that with adequately generalized code and you can write one very thorough analysis that can easily be scaled to as many different groups as you need.
Conclusion
The map() family of functions are super flexible, scalable, and just fun to use. My experience was that the learning curve was a little steep, but only at the beginning. The more you work with the functions the more intuitive they seem and the more I find myself reaching for them. I'm not sure that I've written anything more than just trivial code that hasn't had at least one flavor of map functions present in the past few months. I'd venture to say that the biggest difference in my coding now and in the past is how extensively I use pipelines and map functions. It's already paying dividends in that I can pull any intermediate value out of a pipeline without affecting the pipeline and I can add anything to a pipeline and it still works. Additionally when I write code to analyze performance of my shop, by using these techniques it scales to analyze all the shops for free with no changes needed other than feeding in the bigger dataset.