Why I Use the Julia Programming Language

I love using the Julia Programming Language. I think it is a ridiculously well designed language that lets you get stuff done and do it fast. Julia is well known for its speed, but when I say it lets you get things done fast, I don't mean execution runtime, what I mean is that it is very fast to go from concept to written code that does what you want. The fact that execution time is about as fast as anything else going is just a secondary benefit.
The first programming language I learned was Python. I found the syntax very easy and intuitive. Within a few months of taking a Python 3 programming course from Coursera and the University of Michigan I was off to the races and using programming concepts in general, and Python in specific, in my daily work. I found that there were tons of tasks that I could accomplish that would be unthinkable without using a programming language, and even more tasks that could be accelerated by using open source programming tools.
As I continued to learn I built increasingly more complex tools. Some examples of tools I built include:
- A tool for grouping arbitrary items by latitude and longitude into groups of a specified size tolerance.
- A simulation to process sales data and determine the minimum stock level that would have been needed to ensure parts availability over a given time period.
- A tool that used predictions of rainfall from the national weather service to notify maintenance groups in areas prone to drain blockage/flooding when heavy rain would be expected.
Somewhere along the way as the complexity grew, so to did runtime. I started processing datasets that were > 100,000 rows, or running processes that were highly iterative. Now Python has a very robust ecosystem and lots of tooling to help make it operate very fast, but it isn't traditionally known for its speed, and I was a just the right point in my learning where I was doing enough to be disappointed with the native speed, but not skilled enough to use some of the more advanced techniques to speed up. I had heard about Julia, so I took a look.
It just happened that Julia clicked. The syntax was close enough to Python that I could jump in without going back to square one. At first I found that I missed the convenience of always having a package of ready made functions, structures, or features to call on. With time however I found similar or better packages in the Julia ecosystem and soon only returned to Python occasionally just to reuse some existing code. Not only was my code running faster, but I was also coding faster. I found it easier to translate what I wanted to do into correct code.
Most of what I do involves using tabular data in some way. For that I make extensive use of XLSX.jl, CSV.jl, and DataFrames.jl. These three packages have everything I need to do some pretty extensive analysis. DataFrames.jl in particular is an amazing package. It leverages some of the greatest features of Julia's design to allow you to do insanely complex things insanely fast, and in a very intuitive manner. I remember when I found Pandas for Python how exciting it was, but also how daunting given that there are hundreds of methods and the documentation is gigantic. DataFrames packs all the excitement into one neat and concise package without being daunting. I'm consistently amazed at how, despite appearing to have much fewer features, I can consistently do more in DataFrames, and faster, without ever thinking something is missing.
I love pipelines too! The idea of piping the output of one function to the input of another just clicks in my mind. I think of it like a factory. Inputs in one side outputs out the other through each process to the next.

I also love the power of composability. It is very easy to put things together and get a lot done in a little amount of code. For example, in the cleanDF dataframe above there is a date column, but the column is only text because it was formatted in a "readable" format on the export so it contains values like: Tue Mar 19 10:00:14 EDT 2019. I want to turn these into dates. So first I make a dateformat object that specifies the date format. However since I could have "EDT" or "EST" based on daylight savings I plan ahead and just format it like these values aren't there because I'm going to remove them:
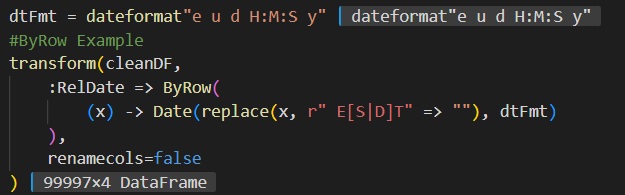
Here you can see I transform cleanDF by operating on the date column (:RelDate) and do a transformation by row (ByRow) where for each value (x) I replace any matches to the regular expression " E[S|D]T" (this says to match anything that starts with a space, has a capital "E" then a capital "S" OR "D" then a capital "T") with a blank value and then format that as a date using my specified format. Finally, don't rename the column, just give me my new dataframe with those values in the :RelDate column. The colon notation for the column name indicates a Symbol type which is an interned string. You could use string notation as well:
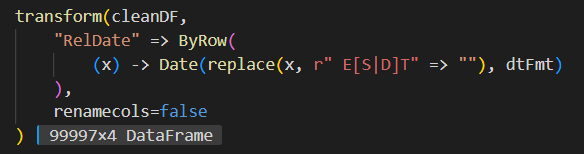
I think that is actually quite a lot done with relatively little fuss. We match and replace regular expressions, parse strings to dates, and put new date values into columns, all in a pretty expeditious manner. It's really a one liner, I just format for readability
Then there is broadcasting. Oh how I love broadcasting. One of my favorite features of Julia is that you can perform operations elementwise on vectors using super simple notation:

Its a short hop from broadcasting to really cooking through data analysis. Since dataframe columns are just vectors we can transform them using broadcasting.
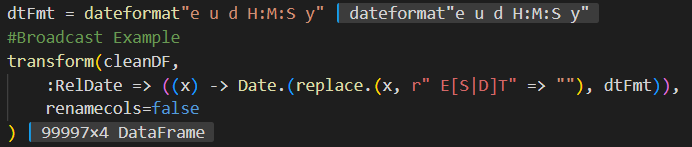
This is the same thing we did in the ByRow version but instead we just broadcast the transformation across the whole column. Notice these broadcast functions are still composable. Broadcasting a replace operation over a vector returns a vector and broadcasting a date transformation over that returned vector just works.
DataFrames.jl uses this idea of transformations of data as composable operations to basically open up any operation you want to perform as if it were any other. What you do is arbitrary and you can even plug in your own functions.
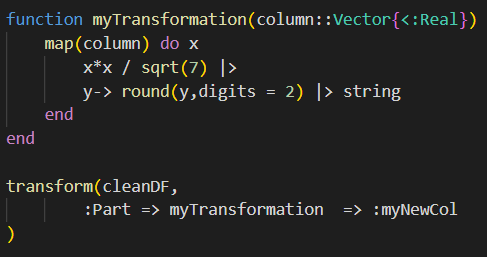
Here is an example where I take in a vector of numbers, square the number and divide by the square root of 7 then round to 2 digits and make it a string. Calling this process on the column of a dataframe is as simple as noting the column, the transformation, and the name of this new column.
There are many more reasons why I love the language, but I think these few illustrate how powerful some of these features can be. DataFrames.jl in particular makes great use of these inbuilt features and makes it so that the features of the package can make use of the amazing flexibility of the language itself.